Paper Review
Paper Review: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
LLM with reasoning via Reinforcement Learning
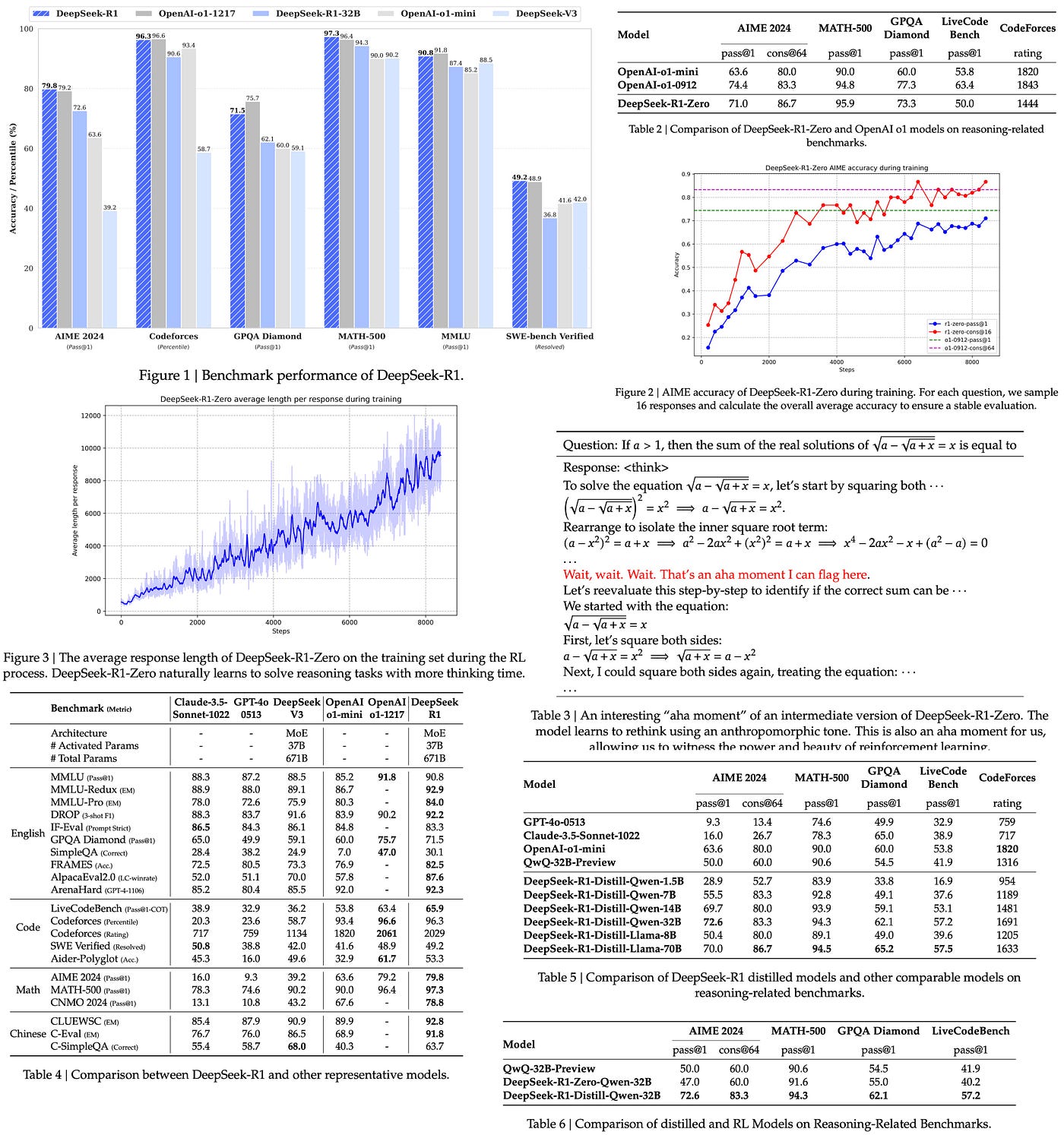
The DeepSeek team introduces two reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero is trained solely through large-scale reinforcement learning without supervised fine-tuning. It showcases strong reasoning capabilities but struggles with issues like poor readability and language mixing. DeepSeek-R1 builds on this by adding multi-stage training and cold-start data before RL to address these issues, achieving performance comparable to OpenAI-o1–1217 on reasoning tasks.
Both models, along with six distilled versions (ranging from 1.5B to 70B parameters), are open-sourced for the research community. The distilled models are based on Qwen and Llama architectures.
The approach
In this paper, the authors demonstrate that the reasoning capabilities of models can be significantly improved through large-scale LR without STF as a cold start. And adding a small amount of cold start data further enhances the performance.
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
For reinforcement learning, the Group Relative Policy Optimization (GRPO) algorithm is used to reduce training costs by eliminating the need for a critic model, which is typically as large as the policy model. Instead, GRPO uses group score-based baselines to estimate advantages. The training objective optimizes the policy model by sampling outputs from the old policy, using clipped probability ratios to stabilize learning, and introducing a KL-divergence penalty to regulate deviations from a reference policy.
A rule-based reward system is adopted to guide the RL process, avoiding neural reward models to prevent reward hacking and reduce training complexity. This system consists of two reward types: accuracy rewards and format rewards. Accuracy rewards assess correctness using deterministic methods, such as verifying math problem solutions or running predefined test cases for programming tasks. Format rewards enforce structured reasoning by requiring the model to present its thinking process within <think> tags.

The training process is further guided by a straightforward template that instructs the model to produce a reasoning process followed by a final answer. This template is deliberately designed to avoid content-specific biases, such as encouraging particular problem-solving strategies, ensuring that the model’s natural reasoning progression can be observed during training.

DeepSeek-R1-Zero demonstrates significant performance improvements on the AIME 2024 benchmark during RL training, with its average pass@1 score increasing from 15.6% to 71.0%, achieving levels comparable to OpenAI-o1–0912.
Comparative analysis across various reasoning benchmarks shows that DeepSeek-R1-Zero can generalize effectively through RL alone. Additionally, applying majority voting further enhances its performance on AIME, boosting its score from 71.0% to 86.7%, surpassing OpenAI-o1–0912.
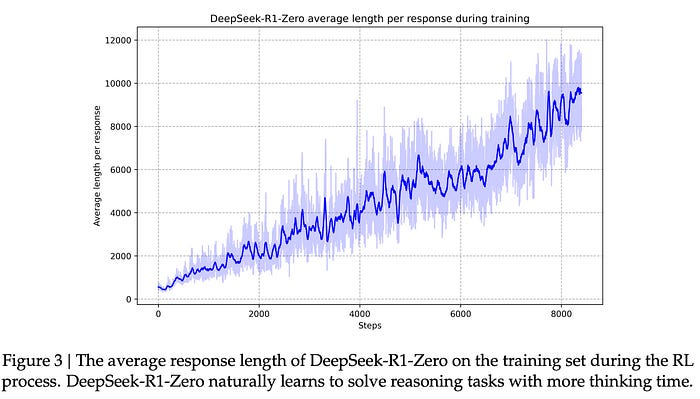
The self-evolution process of DeepSeek-R1-Zero demonstrates how RL enables the model to autonomously enhance its reasoning capabilities.
Throughout the training, DeepSeek-R1-Zero shows consistent improvements in its reasoning efficiency, including extended test-time computation that allows it to generate hundreds to thousands of reasoning tokens. This leads to deeper exploration and refinement of its thought processes.
A key highlight of this process is the spontaneous emergence of sophisticated behaviors, such as reflection, where the model reevaluates its prior steps, and the exploration of alternative problem-solving strategies. These behaviors arise naturally through interaction with the RL environment and significantly enhance the model’s ability to solve increasingly complex tasks with greater efficiency and accuracy.

During the training of DeepSeek-R1-Zero, the researchers observed an “aha moment”, a phase where the model autonomously learned to allocate more thinking time by reevaluating its initial approach to problems. This behavior highlights the power of RL to foster advanced reasoning strategies without explicit instruction, demonstrating the potential of RL to enable artificial systems to develop autonomous and adaptive problem-solving abilities. The “aha moment” was both a milestone in the model’s evolution and an inspiring realization for researchers about the capabilities of RL.
Despite its strong reasoning capabilities and the emergence of sophisticated behaviors, DeepSeek-R1-Zero faces challenges such as poor readability and language mixing. To address these limitations and make the reasoning process more accessible, the researchers developed DeepSeek-R1, which incorporates RL with human-friendly cold-start data to enhance clarity and usability.
DeepSeek-R1: Reinforcement Learning with Cold Start
In the cold-start phase, the model is fine-tuned on thousands of long CoT examples collected using few-shot prompting, reflective and verified outputs from models, and post-processed outputs of DeepSeek-R1-Zero by human annotators. The cold-start data is designed for readability, with a structured format |special_token|<reasoning_process>|special_token|<summary>, addressing language mixing and lack of clarity observed in DeepSeek-R1-Zero.
In the reasoning-oriented RL phase, the model undergoes large-scale RL training to enhance its reasoning abilities in tasks like coding, mathematics, science, and logic. To address language mixing issues in multi-language prompts, a language consistency reward is introduced, which promotes outputs in the target language. Although this alignment slightly reduces task accuracy, it improves readability and aligns with human preferences. The final reward combines task accuracy and language consistency, and RL training continues until the model converges on reasoning tasks.
In the SFT stage, data from reasoning and non-reasoning domains is collected and used to fine-tune the model:
- Reasoning Data: Approximately 600k samples are generated through rejection sampling from the RL-trained checkpoint. This stage expands beyond rule-based rewards to include generative reward models for evaluation. The dataset is curated for readability by filtering out mixed languages, overly long paragraphs, and chaotic outputs.
- Non-Reasoning Data: About 200k samples are collected from domains such as writing, factual QA, self-cognition, and translation using the DeepSeek-V3 pipeline. Simpler queries exclude chain-of-thought reasoning.
In the secondary RL stage, the model is trained to further align with human preferences while refining its reasoning capabilities. This stage includes reasoning data (rule-based rewards guide the model in domains like math, code, and logic), general data (reward models capture human preferences for tasks involving complex and nuanced scenarios), helpfulness (the model’s final summaries are assessed for utility and relevance) and harmlessness (the entire response is evaluated to mitigate risks, biases, and harmful content).
Experiments
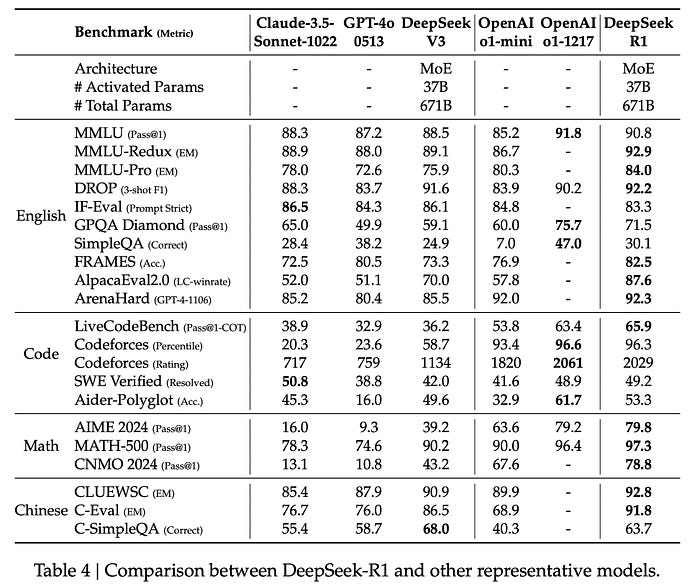
DeepSeek-R1 demonstrates superior performance across various benchmarks, particularly in reasoning and STEM-related tasks:
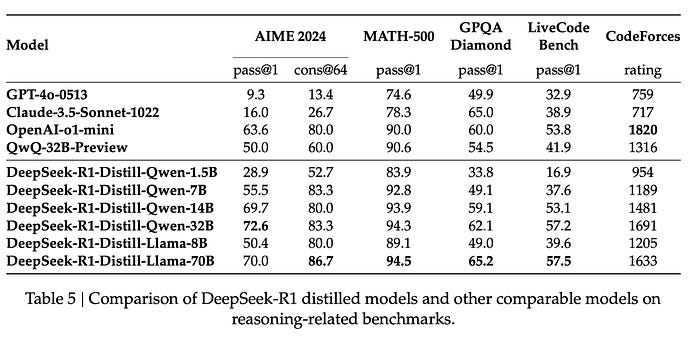

The authors explore whether large-scale RL alone can achieve comparable performance to distillation. Training Qwen-32B-Base with large-scale RL for over 10K steps resulted in DeepSeek-R1-Zero-Qwen-32B, which performed on par with QwQ-32B-Preview. However, the distilled model (DeepSeek-R1-Distill-Qwen-32B) significantly outperformed it across all benchmarks. This highlights two key points: distillation is both cost-effective and highly effective for enhancing smaller models, while achieving similar performance through large-scale RL requires substantial computational resources and may not match the efficiency of distillation. Pushing beyond the current boundaries of intelligence may still require larger base models and advanced RL techniques.
Unsuccessful Attempts:
Process Reward Model aims to guide reasoning tasks by evaluating intermediate steps, but it faces limitations:
- Defining fine-grained steps and assessing their correctness is challenging.
- Automated annotations often yield poor results, while manual annotations hinder scalability.
- Introducing PRM risks reward hacking, complicates training, and increases computational costs.
While useful for reranking or guided search, PRM’s advantages are outweighed by its inefficiencies in large-scale RL setups.
Inspired by AlphaGo, Monte Carlo Tree Search was tried to improve test-time scalability by breaking reasoning tasks into smaller parts. However, this approach encounters challenges:
- Token generation has an exponentially larger search space compared to games like chess, leading to potential local optima.
- Training a high-quality value model to guide the search is difficult, limiting iterative improvement.
Although MCTS can enhance performance during inference with a pre-trained value model, it struggles to iteratively boost model performance due to the complexities of token-based reasoning tasks.
Conclusions and limitations
- General Capabilities: Currently, the capabilities of DeepSeek-R1 fall short of DeepSeek-V3 in tasks such as function calling, multi-turn, complex role-playing, and JSON output.
- Language Mixing: DeepSeek-R1 sometimes mixes English and Chinese
- Prompt Engineering: Few-shot prompting consistently degrades model performance, it is recommended to use zero-shot learning for now
- Software Engineering Tasks: DeepSeek-R1 has not demonstrated a significant improvement over DeepSeek-V3 on software engineering benchmarks.
